Show your work
Dedicated to necessity, our mother

When I had the opportunity to be on Reid Hoffman’s Masters of Scale podcast, he mentioned that AI companies needed to come up with a phrase that would briefly describe their differentiators. I quickly quipped,
“Bast AI builds AI that shows its work.”
I have pride and sorrow in having this as Bast’s most understood differentiator. Pride in that we have built software designed to explain and show the work and choices made. Sorrow in that showing your work is not currently the default modality for AI systems. It’s absurd to see how much money has been spent on AI systems that aren’t explainable. My sorrow is short-lived because I do not doubt that Bast’s version of AI software will be the default; it is the next generation of AI systems.
AI systems that can show and explain how and why they predict the answer are trusted systems; these systems are partners for humans and thus will be widely adopted. Adoption is the first of many problems that we have solved with our software. This blog is dedicated to necessity; she is the mother of invention and is beautiful only after you have had the pleasure and tenacity to do the work and admire the frustration. The only way out is through.
My CTO and I were on the phone with a prospective new teammate for Bast, and after 90 minutes of a deep dive, he relayed the following.
“I looked at your website and thought to myself, they purport to solve all the issues with LLMs and GenAI. But after 90 minutes of the deep dive, it occurred to me that you have not only solved all these issues, but you are showing me how much experience you have that others lack. You have worked to solve problems that most AI system developers will never even encounter.”
This engineer reminded me of something I often forget. I have created and led teams that have fixed more AI systems than others have built. I have anecdotes, battle scars, and stories that cover the range of designing, developing, deploying, testing, duct-taping, and supporting AI systems.
I am a victim of the Dunning Kruger bias — I know how much I don’t know about AI systems. Most — if not all of the data scientists/developers I have worked with, trained, or encountered have asked me the golden question.
“How can I belong to a team that gets to deploy their model into production and have it be used.”
My answer is the same — join a delivery team in a large corporation and solve your client’s problems using data and the scientific method. Single developers design or build their models; most never make it to production. There is a reason for this: AI is a team sport, people desperately believe there is an easy button and humans value what they pay for.
Does the world realize that a diverse, experienced team of humans is needed to deliver an AI system that generates a business outcome?
Thanh Lam, my CTO, and I have worked together for over two decades and solved more business problems using ] elbow grease and willingness to talk to the creators of the data than anyone else I know. We are really good at making sure what we do is approachable and understood by every person on the team, especially the sponsors who are paying our bill. We are also used to working on a large team for the benefit of our clients, and often, that team has never worked with data.
Ironically, so many “data” people have not waded through the data to understand what was happening in the systems. Our necessity to solve our clients’ problems taught us how to innovate in so many ways and to be curious about how we can do something better the next time and how we can do more with less. These are the drivers in everything we have built: an insatiable curiosity about what the data says, a frugality with non-renewable resources, a team including domain experts who understand the problem we are solving, and a desire to use the right tool for the right problem. We try to fit form with function and tap the power of limits.
Back when we were still at IBM, and I was working to create an understanding in data scientists that they needed to start with the business problem they were solving, I got an inkling of what was to come. This was back in 2012, and we started creating a profession and a career path for data scientists that would allow them to test their mettle against other certified data scientists and have their work peer-reviewed.
Our data science profession requires projects that show the scientist understands the entire cycle of implementing a data science project with a business outcome. In 2015–2016, everyone wanted to do the latest, most incredible thing — first predictive analytics and then machine learning and deep learning. Because GPUs or graphical processing units could process large amounts of data, it became reasonable for people to shove large datasets into “piles of linear algebra” and have the AI system output the “features or predictors” of the data set. There are obvious problems in not understanding your dataset — it means that you likely don’t understand the problem you want to solve and don’t do the work to see if you have the suitable dataset with the right variation to solve the business problem.
The more obvious issue with this approach is quite apparent — if you don’t sanitize or understand your inputs, you have no control over your outputs.
It would be reductive and unfair of me to state that nothing has come of this hopefully brief quest for larger GenAI models that require so much of our earth’s resources to build and train. We now live in a world where many more humans know what AI is. For this alone, I am thankful because we must have as many of the 8 billion humans aware of what AI is and what it can do for our ecosystem. I would prefer we had a representative sample, and 1.6B people are working to develop and deliver AI systems.
TL;DR
Contact us if you want to replace that LLM or GPT model with a for-real full-stack AI brain. If you want a quick guide, use the infographic below or copy and paste these questions into any generative AI system to see whether the answers lead you back to Bast. Or if you want to see the answers I got from OpenAI.
Questions:
Can you tell me the difference between an AI system that includes a data pipeline vs. one that doesn’t?
Can you tell me the difference between an AI system that includes a knowledge graph to ground context and increase NLU vs. one that doesn’t?
Can you tell me the difference between an AI system that includes a data pipeline for a feedback loop vs. one that doesn’t?
Can you tell me the difference between an AI system that uses microservices code architecture to scale over Kubernetes clusters vs one that doesn’t?

We at Bast AI have created an AI engine designed to show its work; this is the best evidence that we have done the work. I urge you to please ask the current dominant AI providers to explain why they are not showing their work. Have they done it?
Let’s start with the data. I wish I were joking about data scientists shoving large amounts of data into statistical models without knowing, understanding, or, in most instances, even inspecting or looking at the data used in the model. Knowing what I know about the magic that comes from understanding the stories in data makes me sad for the folks who were likely forced to do this type of “data science.” Due to massive misunderstanding between the business and technology folks, so many data scientists were trained that the “objective” measures of accuracy and precision were the only ways to understand whether a model was good enough. Many are forced to get to the “right” number. I like to show this picture (below) and try my best to explain how beating up engineers to get the model to show the highest accuracy is not helpful to your business. Any data scientist can torture the data to force it to say anything you want — often known as overfitting the data to the model.

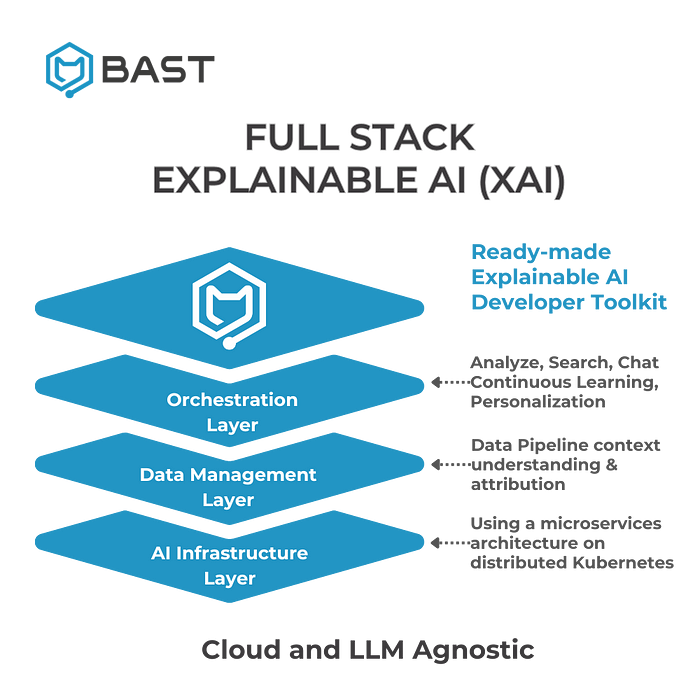
At Bast AI we make sure that all of your data stays in your control and we provide you all the tools to process your data behind your firewall. Bast’s AI engine incorporates a data pipeline that processes your data. Let me say this again. Bast AI’s engine has a data pipeline to process your data. This is not something that is included when you sign up for a 20$/month subscription to get access to the GPT models APIs. Having a data pipeline means that you have full control over any data that you would like to process and with Bast’s AI Engine you get it as a part of our full stack Explainable AI.
A data pipeline is often sold as a seperate revenue stream for most systems and it is sized out as an afterthought. This is the first of many mistakes most folks make when they attempt to implement or deploy AI systems. The data pipeline is the most difficult and truly the biggest most important feature of your AI system. The data that is used in your AI system is the most important part of getting your AI system to work.
In order to have AI models that data can flow over, as data is a stream of changing artifacts, you should understand what your data is and store it in an information system, preferably with all of the versions of the data artifacts. Without a data storage, you have no persistent state or memory and without a data pipeline pipeline you can’t process the output of your models as a feedback loop. You cannot make your model learn from the interactions you have made with it. You, the human, have to change your question to get a different answer.
Our Bast data pipeline is one of the best things that we have ever created. We can save so much time and angst for folks, we know this because we have built it after experiencing so much time and angst in processing data for our clients. We start by preprocessing the data because we have had to invent a way to use all the data, which is predominantly very low-quality.
The Bast AI system was built to for unstructured data, PDFs, word documents, transcripts, etc. This wave of AI modernity (language-models) is all about unstructured data, and for us — the uglier, the better. Understanding raw data or getting the data directly at the source is one of our specialties, bring us your ugly unstructured data and we can help you know it. We preprocess the data to ensure we can use the correct data to solve the right problem. Don’t worry; we keep all the versions of the data and show our work for all the transformations made to the data. This is our secret sauce: this work we do upfront to process your data and how we know we have built an AI system with full explainability. We can show you all our work — the full provenance and lineage of the data because our process is built to sanitize the models' inputs so you have output assurance. This would be the first way to test whether someone has built an AI system designed for humans, designed to explain and show its work. Ask for the images, pictures, or evidence of the original raw data ingested into an AI model you are using.
Our data pipeline leverages an open-source framework called DVC, or data version control. Our data pipeline takes your data and organizes it into a system of record, which becomes the base of the AI model’s inputs and can even contain the output for feedback. This well-organized, labeled, and versioned data is the operating system for all the AI models. We even version the models, solving for the ability for forward and backward compatibility.
Solving for forward and backward compatibility means you don’t have to experience a software version break when a new release is installed. We also use the craft of DevSecOps and provide a CICD pipeline so you can modify your application without having your users experience downtime. We apply versioning — or the retention of every version- to the entire system, including the ontology.

The data pipeline also produces an ontology — or knowledge graph — that acts as a map for your system of record. By keeping versions of your ontology or map of your system of record — we can go back in time and tell you how and why the AI system gave you that output on that day. There is nothing like this in the market today, because most people dont have our experience in supporting systems where a person needs to go back 7 years to see why someone made a decision. It is urgent that we start to think about the implications of doing so.
The ontology provides contextual understanding of the data we are processing and allows the AI system to “understand” what the human is asking for. There is no understanding for an AI system that does not carry the relevant context to understand against. The contextual understanding of our Bast AI system is superior to every GPT model and every RAG system and every vector database. This is not my opinion it is a fact based on understanding the correct way to engineer a system that can have “NLU” or natural language understanding. The Generative AI models were not built to understand, they are built to generate. Extending GenAI models with a Knowledge Graph for understanding is just becoming popular in academia, but since we have experience, Bast has written the code to automate the use of ontologies for understanding or ontological NLU into our software. Software that is built using TDD or test driven development and using an extensible microservices code architecture.
The Bast team has a combined 100 years of solution integration with software means we build software that does not break when new versions are released; I’m pretty sure no one else can claim it today for full stack AI. Ask us or your software provider for their test case coverage for their code base. By using test driven development, we write the test case before we write the code so we know what we want the code to do and how to test that the code is doing what we want it to do.
Most data scientists also need the SW engineering chops to understand that they need a modern-day code architecture to express their inputs and outputs of the models as an API. Another great question to ask your team is if they have considered how the microservices need to be laid down to scale appropriately against the cloud services infrastructure architecture. Do they have a load balancer to spin up the Kubernetes clusters when required? Many SW engineers don’t also have the training to understand how to build container-based systems that can work on any cloud provider or how to distribute the load on the cloud infrastructure architecture using Kubernetes. To quote Reid Hoffman from the podcast I cited at the beginning of this blog.
“If you don’t know what she’s talking about, go look it up” Reid Hoffman
My team grew up without unlimited computing power, and the cost of the entire system had to be accounted for when we showed our profit. Another great question—what is your cradle-to-grave implementation or entire lifecycle, otherwise known as your total cost of ownership of your AI system? Have you considered what others could do with the proverbial “space junk” you have created and abandoned on that VM?
I could go on, but I have already made this blog long enough. Here is a link to the Scaled Data Science Method that I helped to create to talk about how — what seems to be easy and could be done by an intelligent human and GPT — needs to be done by a team of people, people with experience to build software, build models, test and deploy those models and can explain WHY they built the system in the way that they did.
We should ask everyone to explain WHY something has been built. Was it for a problem they were solving for a client who paid for them to solve it?
Most AI developers never see their model go into production or the feedback loop (if written) is used; they need to be trained to create the proper AI infrastructure or SW architecture and require data engineers to produce well-ordered labeled data sets. Most people, even those investing billions of dollars, need to be made aware they need a diverse and experienced team of people and the skills those humans need to become part of the well-performing team necessary to build, test, deploy, and support an AI system.
In my world, every person is accountable for the AI system’s impact on the world. It makes it much easier to do the work and show that it has been done.
Join us.
